Visual Localization
The Challenge: The “Memorization” Trap
For applications like AR/VR, autonomous driving, and robotics, a device needs to know exactly where it is in 3D space just by looking through its camera. Traditionally, AI models (Absolute Pose Regression) have tried to guess this 6-DoF (Degrees of Freedom) camera pose directly from an image. However, these models act like black boxes: instead of truly understanding 3D geometry, they just memorize the training photos. If they encounter a new angle or viewpoint, they often fail.
The Innovation: Geometric Representation Regression
My project, GRLoc (Li et al., 2025), asks a different question: What if we teach the AI to understand spatial geometry the same way a computer graphics engine does, but in reverse?
Recently, technologies like NeRF and 3D Gaussian Splatting have revolutionized how we generate 3D images by explicitly modeling light rays and 3D points. GRLoc flips this process on its head. Instead of rendering an image from a known location, GRLoc takes a single 2D image and explicitly reconstructs the underlying 3D geometry to figure out where the camera must be.

How It Works
Instead of a single, messy guess, GRLoc breaks the problem down into two distinct, decoupled physical properties:
-
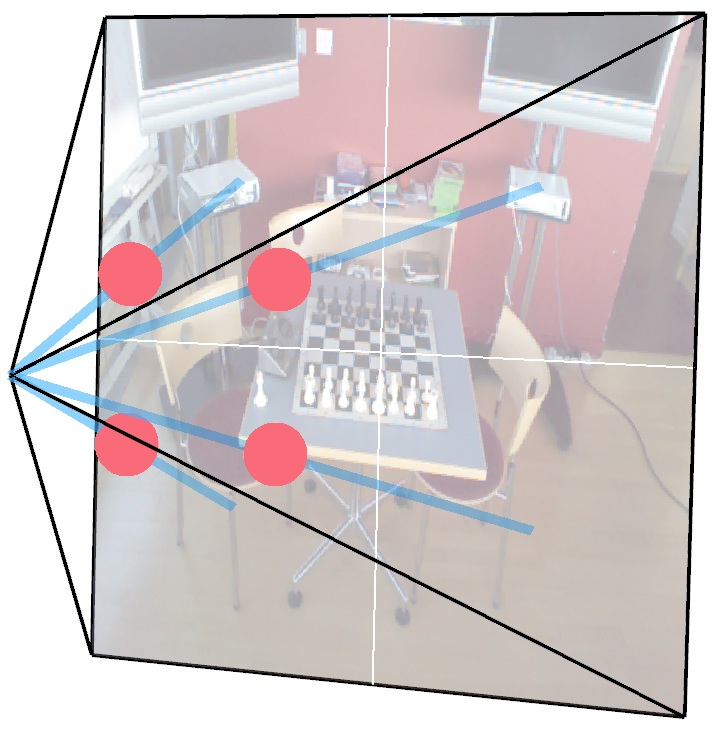
The “Where am I looking?” (Rotation): The network predicts the direction of 3D light rays (raymaps).
-
The “Where am I standing?” (Translation): The network maps out 3D spatial points (pointmaps).
By separating these two tasks, we prevent the model from getting confused by competing objectives. Finally, a mathematical solver takes these geometric clues and deterministically calculates the exact camera pose.
The Impact
By blending the pattern-recognition power of neural networks with the hard, unbending rules of 3D geometry, GRLoc stops memorizing and starts understanding. This method achieved state-of-the-art performance on major benchmarks (7-Scenes and Cambridge Landmarks), proving that embedding real-world physics into AI models leads to more robust, reliable, and generalizable spatial awareness.
References
2025
-
 GRLoc: Geometric Representation Regression for Visual LocalizationarXiv preprint arXiv:2511.13864, 2025
GRLoc: Geometric Representation Regression for Visual LocalizationarXiv preprint arXiv:2511.13864, 2025